# 离线语音听写 Android SDK 文档
# 1、简介
语音听写,是基于自然语言处理,将自然语言音频转换为文本输出的技术。语音听写技术与语法识别技术的不同在于,语音听写不需要基于某个具体的语法文件,其识别范围是整个语种内的词条。
语音听写详细的接口介绍及说明请参考: MSC Android API 文档 (opens new window)。
在集成过程中出现错误,请优先查询SDK&API 错误码查询 (opens new window)。如有疑问,请提交工单 (opens new window)进行咨询,也可登录讯飞开放平台论坛 (opens new window)与广大开发者共同学习和交流
# 2、SDK集成指南
# 2.1、Demo运行步骤
根据官网控制台 (opens new window)提示,直接下载SDK,SDK中包含简易可运行的Demo。如下图所示:
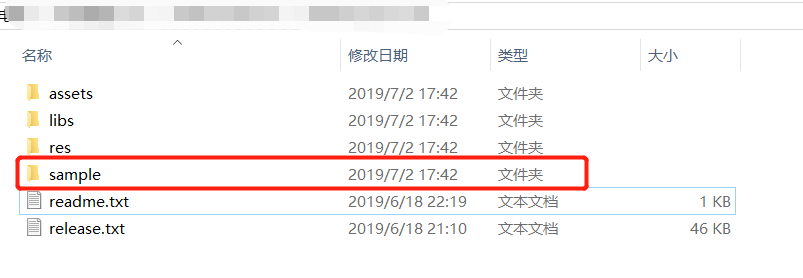
下载完SDK后,解压至相应的路径。
注:使用demo测试时,需将res中除layout外资源拷贝到demo中assets相应的路径下
以Android Studio集成开发工具为例,测试时建议直接用真机进行测试。
# 方法一(导入project方式):
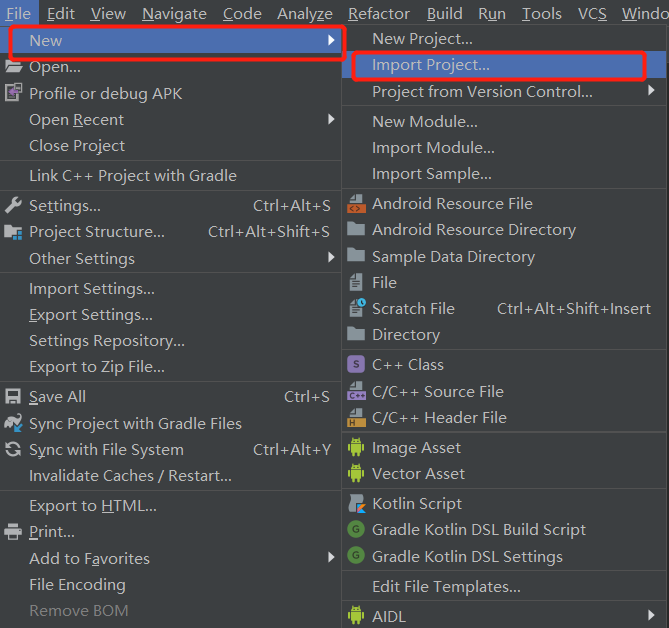
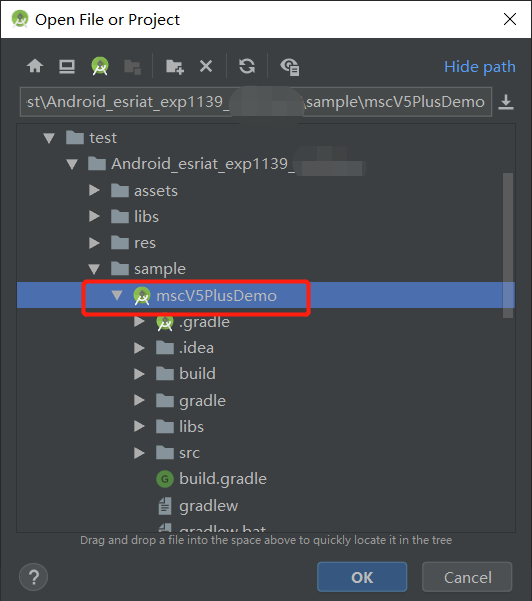
打开Android Studio,在菜单栏File--->new--->import project当前解压sdk路径,使用离线服务能力选择导入mscV5PlusDemo,如下图所示:
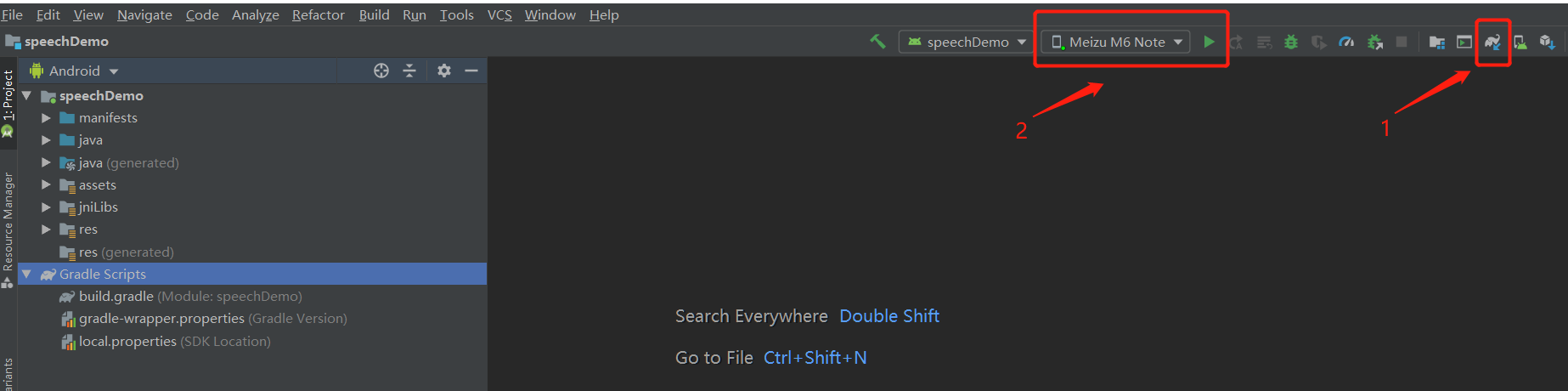
导入成功之后sync编译下,编译无误可连接手机,开启手机USB开发调试模式,直接在Android Studio运行导入的mscV5PlusDemo,最后生成的apk可直接安装在对应的手机上,如下图所示:
如果编译时出现“ERROR: Plugin with id 'com.android.application' not found.”错误,请在build.gradle文件中添加以下代码。
buildscript {
repositories {
google()
jcenter()
}
dependencies {
//版本号请根据自己的gradle插件版本号自行更改
classpath 'com.android.tools.build:gradle:3.4.0'
// NOTE: Do not place your application dependencies here; they belong
// in the individual module build.gradle files
}
}
如在导入项目中还出现其他问题,可参考帖子:安卓demo常见错误排查 (opens new window)
# 方法二(导入module方式):
打开Android Studio,在菜单栏File--->new--->import Module当前解压sdk路径,使用离线服务能力选择导入mscV5PlusDemo,导入成功之后sync编译下,编译无误可连接手机,开启手机USB开发调试模式,直接在Android Studio运行导入的mscV5PlusDemo,最后生成的apk可直接安装在对应的手机上。
# 2.2、项目集成步骤
# 2.2.1、SDK包说明
《Android SDK目录结构一览》
- manifests:
- android配置应用权限文件
- sample:
- 相关离线能力demo(离线语音听写IatDemo)
- assets:
- SDK相关资源配置文件
- Libs:
- 动态库和jar包
- res:
- UI文件和相关布局文件xml
- readme说明(必看)
- release 版本说明
# 2.2.2、导入SDK
将在官网下载的Android SDK 压缩包中libs目录下所有子文件拷贝至Android工程的libs目录下,如下图所示:
备注:
- arm版本已经逐步淘汰了,arm架构的推荐使用armeabi-v7a。
- 如果您需要将应用push到设备使用,请将设备cpu对应指令集的libmsc.so push到/system/lib中。
- 使用demo测试时,需将res中除layout外资源拷贝到demo中assets相应的路径下。
- .集成到项目,需要将sdk中Demo/src/main/下文件拷贝到项目main中,以AS为例,且需要在项目main文件夹下新建Jnilibs并拷贝libmsc.so。
- msc.jar需要拷贝至项目libs下,并且右键jar添加Add As Library。
- sdk下文件夹main/assets/,自带UI页面(iflytek文件夹)和相关其他服务资源文件(语法文件、音频示例、词表),使用自带UI接口时,可以将assets/iflytek文件拷贝到项目中。
# 2.2.3、添加用户权限
在工程 AndroidManifest.xml 文件中添加如下权限
<!--连接网络权限,用于执行云端语音能力 -->
<uses-permission android:name="android.permission.INTERNET"/>
<!--获取手机录音机使用权限,听写、识别、语义理解需要用到此权限 -->
<uses-permission android:name="android.permission.RECORD_AUDIO"/>
<!--读取网络信息状态 -->
<uses-permission android:name="android.permission.ACCESS_NETWORK_STATE"/>
<!--获取当前wifi状态 -->
<uses-permission android:name="android.permission.ACCESS_WIFI_STATE"/>
<!--允许程序改变网络连接状态 -->
<uses-permission android:name="android.permission.CHANGE_NETWORK_STATE"/>
<!--读取手机信息权限 -->
<uses-permission android:name="android.permission.READ_PHONE_STATE"/>
<!--读取联系人权限,上传联系人需要用到此权限 -->
<uses-permission android:name="android.permission.READ_CONTACTS"/>
<!--外存储写权限,构建语法需要用到此权限 -->
<uses-permission android:name="android.permission.WRITE_EXTERNAL_STORAGE"/>
<!--外存储读权限,构建语法需要用到此权限 -->
<uses-permission android:name="android.permission.READ_EXTERNAL_STORAGE"/>
<!--配置权限,用来记录应用配置信息 -->
<uses-permission android:name="android.permission.WRITE_SETTINGS"/>
<!--手机定位信息,用来为语义等功能提供定位,提供更精准的服务-->
<!--定位信息是敏感信息,可通过Setting.setLocationEnable(false)关闭定位请求 -->
<uses-permission android:name="android.permission.ACCESS_FINE_LOCATION"/>
<!--如需使用人脸识别,还要添加:摄相头权限,拍照需要用到 -->
<uses-permission android:name="android.permission.CAMERA" />
注意:如需在打包或者生成APK的时候进行混淆,请在proguard.cfg中添加如下代码:
-keep class com.iflytek.**{*;}
-keepattributes Signature
# 2.2.4、接入
为保证用户个人隐私,防止APP不当收集用户信息,我们强烈建议您遵守以下流程接入本SDK保证合规,防止因调用时机不当引发的后果,例如但不限于:APP被应用市场下架等。
(1)您需要确保贵APP有《隐私政策》,并且在用户首次启动App时就弹出《隐私政策》争得用户同意。
(2)您务必在App的《第三方共享清单及SDK目录》中告知用户MSC SDK收集的个人信息类型以及MSC SDK隐私政策。
(3)个人信息收集说明:MSC SDK需要收集唯一设备识别码(android ID)以提供能力授权服务。
(4)隐私政策 (opens new window)请点击查看。
(5)您务必严格遵守如下调用步骤,确保用户同意《隐私政策》之后,且在用户主动使用本SDK提供的各项功能时再进行相关函数调用。
确保App启动后,在用户阅读并同意《隐私政策》并取得用户授权之后,在用户使用SDK功能时,方可调函数SpeechUtility.createUtility(SpeechApp.this,xxxx)以使用MSC SDK。反之,如果用户不同意《隐私政策》授权,则不允许调用SpeechUtility.createUtility(SpeechApp.this,xxxx)初函数。
参考示例:SDK demo源码中获取到《隐私政策》的用户授权,后续的SDK demo函数SpeechUtility.createUtility(SpeechApp.this, xxxx)建议在用户使用SDK功能时进行使用。
接入即创建语音配置对象,只有接入后才可以使用MSC的各项服务。接入代码如下:
// 将“12345678”替换成您申请的APPID,申请地址:http://www.xfyun.cn
// 请勿在“=”与appid之间添加任何空字符或者转义符
// appid 必须和下载的SDK保持一致,否则会出现10407错误
// 应用程序入口处调用,避免手机内存过小,杀死后台进程后通过历史intent进入Activity造成SpeechUtility对象为null
SpeechUtility.createUtility(context, SpeechConstant.APPID +"=12345678");
# 2.3、UI设置
sdk提供了两种识别方式,分别为带UI识别和无UI方式:
# 2.3.1、无UI识别
//接入识别无UI识别对象
//使用SpeechRecognizer对象,可根据回调消息自定义界面;
mIat = SpeechRecognizer.createRecognizer(IatDemo.this, mInitListener);
//设置语法ID和 SUBJECT 为空,以免因之前有语法调用而设置了此参数;或直接清空所有参数,具体可参考 DEMO 的示例。
mIat.setParameter( SpeechConstant.CLOUD_GRAMMAR, null );
mIat.setParameter( SpeechConstant.SUBJECT, null );
//设置返回结果格式,目前支持json,xml以及plain 三种格式,其中plain为纯听写文本内容
mIat.setParameter(SpeechConstant.RESULT_TYPE, "json");
//此处engineType为“cloud”
mIat.setParameter( SpeechConstant.ENGINE_TYPE, engineType );
//设置语音输入语言,zh_cn为简体中文
mIat.setParameter(SpeechConstant.LANGUAGE, "zh_cn");
//设置结果返回语言
mIat.setParameter(SpeechConstant.ACCENT, "mandarin");
// 设置语音前端点:静音超时时间,单位ms,即用户多长时间不说话则当做超时处理
//取值范围{1000~10000}
mIat.setParameter(SpeechConstant.VAD_BOS, "4000");
//设置语音后端点:后端点静音检测时间,单位ms,即用户停止说话多长时间内即认为不再输入,
//自动停止录音,范围{0~10000}
mIat.setParameter(SpeechConstant.VAD_EOS, "1000");
//设置标点符号,设置为"0"返回结果无标点,设置为"1"返回结果有标点
mIat.setParameter(SpeechConstant.ASR_PTT,"1");
//开始识别,并设置监听器
mIat.startListening(mRecogListener);
# 2.3.2、带UI识别
// 接入听写Dialog,如果只使用有UI听写功能,无需创建SpeechRecognizer
// 使用UI听写功能,请根据sdk文件目录下的notice.txt,放置布局文件和图片资源
mIatDialog = new RecognizerDialog(IatDemo.this, mInitListener);
//以下为dialog设置听写参数
mIatDialog.setParams("xxx","xxx");
....
//开始识别并设置监听器
mIatDialog.setListener(mRecognizerDialogListener);
//显示听写对话框
mIatDialog.show();
# 3、参数设置
# 3.1、基础参数
| 参数名称 | 名称 | 说明 |
|---|---|---|
| engine_type | 引擎类型 | 离线语音听写默认为:local |
| asr_res_path | 离线识别资源 | 离线命令词识别需要使用本地资源,通过此参数设置本地资源所在的路径 值范围:有效的资源文件路径 默认值:null |
| result_type | 返回结果格式 | 主要分为三种:json,xml,plain 默认:json |
| language | 语言 | 离线语音听写仅支持中文:zh_cn |
| accent | 方言 | 离线语音听写仅支持:mandarin |
| asr_ptt | 标点符号 | (仅中文支持)标点符号添加 1:开启(默认值) 0:关闭 |
| vad_bos | 前端点检测 | 开始录入音频后,音频前面部分最长静音时长,取值范围[0,10000ms],默认值5000ms |
| vad_eos | 后端点检测 | 开始录入音频后,音频后面部分最长静音时长,取值范围[0,10000ms],默认值1800ms。 |
# 3.2、离线资源路径设置
resource设置中包含两个资源,common.jet 和 sms_16k.jet, 从资源配置中可以看出,目前离线听写仅支持16k音频
private String getResourcePath(){
StringBuffer tempBuffer = new StringBuffer();
//识别通用资源
tempBuffer.append(ResourceUtil.generateResourcePath(this, ResourceUtil.RESOURCE_TYPE.assets, "iat/common.jet"));
tempBuffer.append(";");
tempBuffer.append(ResourceUtil.generateResourcePath(this, ResourceUtil.RESOURCE_TYPE.assets, "iat/sms_16k.jet"));
return tempBuffer.toString();
}
# 4、常见问题
# 支持哪些语言?
答:目前只支持中文(普通话)。
# 离线语音听写是否可以试用?
答:可以的,目前提供10个装机量可以免费试用,试用期90天。
# 离线语音听写是否支持个性化热词功能?
答:目前不支持。
# 离线语音听写支持的音频格式是什么?
答:音频长度:小于20s;采样率16KHz;采样精度:16bit;声道单声道,音频文件的录制和格式确认(推荐使用Cool Edit Pro工具)。
# 离线语音听写识别率低是什么原因?
答:请检查上传的音频格式和属性是否满足pcm、wav对应16KHZ,16bit的音频,如果离线语音听写效果达不到您项目的要求,建议使用在线听写。
# 支持平台是什么?
答:目前只支持Android平台,不支持其他平台。

