# 语音听写 Linux SDK 文档
# 1、简介
语音听写,是基于自然语言处理,将自然语言音频转换为文本输出的技术。语音听写技术与语法识别技术的不同在于,语音听写不需要基于某个具体的语法文件,其识别范围是整个语种内的词条。在听写时,应用还可以上传个性化的词表,如联系人列表等,提高列表中词语的匹配率(见后面章节)。
语音听写详细的接口介绍及说明请参考: MSC Linux API 文档 (opens new window), 在集成过程中如有疑问,可登录讯飞开放平台论坛 (opens new window),查找答案或与其他开发者交流。
小语种:
- 目前小语种已经适配日语、俄语、西班牙语、法语、韩语,其他小语种敬请期待!
# 2、SDK集成指南
# 2.1 Demo运行步骤
1.在控制台下载对应sdk
2.进入sdk内samples/iat_online_sample目录source 64bit_make.sh或32bit_make.sh, 视系统位数选择
3.运行成功后进入sdk bin目录下cd ../../bin/,运行./iat_online_sample即可看到运行结果
# 2.2 项目集成步骤
# 2.2.1 sdk包说明
《SDK目录结构一览》
- bin:
- msc(生成msc日志)
- wav(符合标准的音频文件样例)
- 相关资源文件
- doc:
- 相关技术文档
- include:
- 调用SDK所需头文件
- libs:
- x86/libmsc.so(32位动态库)
- x64/libmsc.so(64位动态库)
- samples:
- iat_online_sample(语音听写示例-已录制音频)
- iat_online_record_samplele(语音听写示例-从麦克风录入)
注意:
- 为了减少SDK包在应用中占用的大小,官网在下载单个功能的SDK包时, 可能并不包含其他功能,如下载合成的SDK包时,可能不包含听写或唤醒等功能,因此在运行未包含功能的示例时,可能会报错。对此请下载对应功能的SDK,或下载组合的SDK包。
# 2.2.2 sdk导入
- 新建目录Demo,将SDK中bin,include,libs文件夹复制到新建工程“Demo”文件夹下
- 在demo目录新建文件demo.c,详细源码请参考samples中对应的语音示例
- 在demo目录下,创建Makefile文件,具体参见samples下的Makefile,修改路径和目标文件即可
- 将samples目录下“32bit_make.sh”文件或者“64bit_make.sh”文件拷到demo目录下,修改libmsc.so库搜索路径
- cd到demo目录下,执行“source 32bit_make.sh”或者 “source 64bit_make.sh”完成编译
- cd到bin目录下运行目标文件,SDK启动后,bin/msc目录下会生成日志(注意:msc文件夹下需有msc.cfg文件)
# 2.2.3 API调用流程
语音听写主要API调用流程如下图所示:
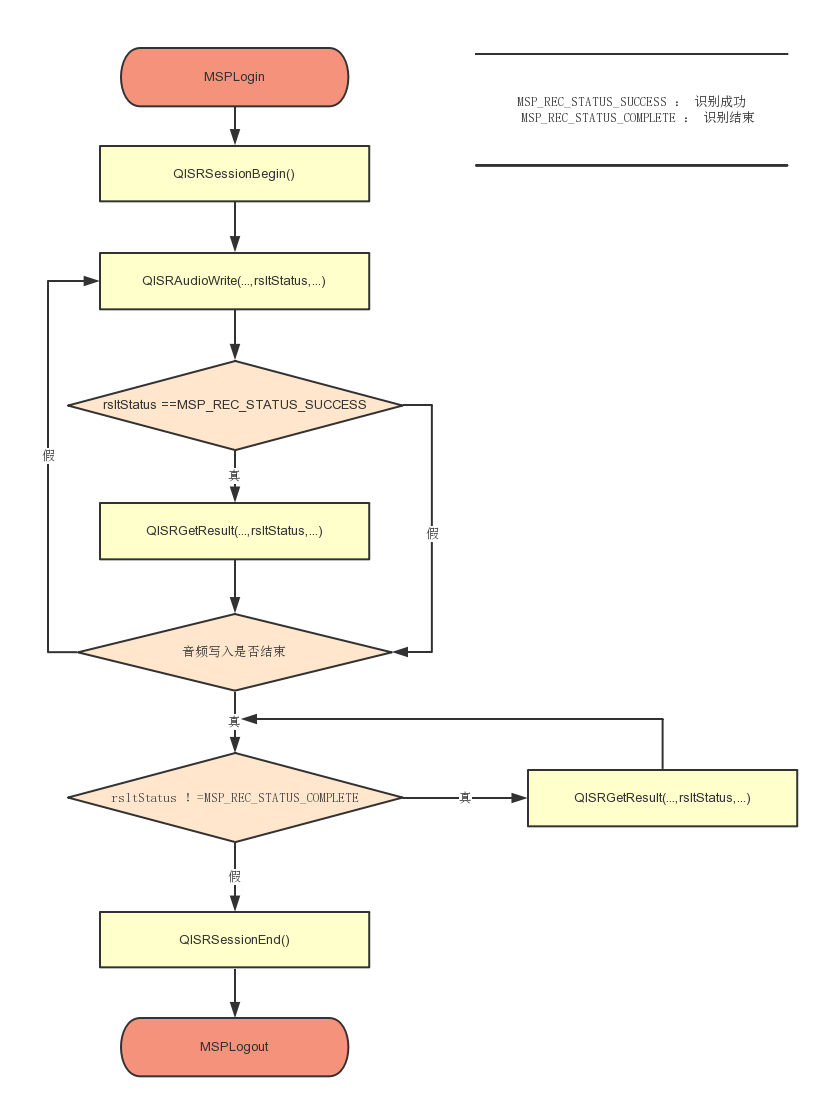
详细代码调用请参考 Samples中的 iat_online_sample(语音听写示例),API详细描述请参考API文档 (opens new window)
# 2.3 参数与说明
# 2.3.1 动态修正
自2019/8/16起,高阶功能-动态修正免费开放!可到这里 动态修正效果 (opens new window) 在线体验
- 未开启动态修正:实时返回识别结果,每次返回的结果都是对之前结果的追加;
- 开启动态修正:实时返回识别结果,每次返回的结果有可能是对之前结果的的追加,也有可能是要替换之前某次返回的结果(即修正);
- 开启动态修正,相较于未开启,返回结果的颗粒度更小,视觉冲击效果更佳;
- 使用动态修正功能直接设置相应参数即可使用,参数设置方法:dwa=wpgs ;
- 动态修正功能仅 中文 支持;
未开启与开启返回的结果格式不同,若设置了动态修正参数:dwa=wpgs(仅中文支持),会有如下字段返回:
| 参数 | 类型 | 描述 |
|---|---|---|
| pgs | string | 开启wpgs会有此字段 取值为 "apd"时表示该片结果是追加到前面的最终结果;取值为"rpl" 时表示替换前面的部分结果,替换范围为rg字段 |
| rg | array | 替换范围,开启wpgs会有此字段 假设值为[2,5],则代表要替换的是第2次到第5次返回的结果 |
# 2.3.2 代理服务器设置
在MSPLogin接口的params参数中添加:
net_type=custom, proxy_ip=<host>, proxy_port=<port>
其中,<host>,<port>替换为实际的代理服务器地址和端口。
例如:MSPLogin(NULL, NULL, "appid = 12345678, net_type=custom, proxy_ip=192.168.1.2, proxy_port=8080"); 注意:各参数间,以英文逗号分隔。
接口原型: int MSPLogin(const char* usr, const char* pwd, const char* params)
注意: 若在设置代理参数后,使用语音服务过程中,报错10204/10205/10212等网络异常错误时,请查阅以下内容,做出相关操作:
- 讯飞语音SDK的通信协议使用的是标准HTTP1.1协议,其代理协议使用的是标准HTTP代理协议。
- 代理服务器需要支持全双工多问多答方式,即 pipeline 模式。
- 代理服务器不能对80端口做限制,不能对如下域名做拦截: hdns.openspeech.cn scs.openspeech.cn open.xf-yun.com dev.voicecloud.cn
- 需要确保代理服务器只负责转发数据包,不能改变数据包的完整性和时序性。
- 代理服务器在转发数据包时,不能在HTTP协议头部添加 IE6 标识头。
# 2.3.3 常用参数说明
以下为常用参数说明,更多参数设置请参考API文档 (opens new window)
| 参数 | 名称 | 说明 |
|---|---|---|
| language | 语言 | 目前Linux SDK支持 zh_cn:中文 en_us:英文 ja_jp:日语 ko_kr:韩语 ru-ru:俄语 fr_fr:法语 es_es:西班牙语 注:小语种若未授权无法使用会报错11200,可到控制台-语音听写(流式版)-方言/语种处添加试用或购买。 |
| sample_rate | 音频采样率 | 可取值:16000,8000 默认值:16000 |
| accent | 语言区域 | 可取值 : mandarin:普通话 lmz:四川话 默认值:mandarin 注:更多方言可在控制台添加开通 |
| vad_eos | 允许尾部静音的最长时间 | 0-10000毫秒。默认为2000如果尾部静音时长超过了此值,则认为用户音频已经结束 |
| dwa | 动态修正 | 可取值:wpgs 详情可参考上方动态修正说明 |
| nbest | 多候选-句级 | 取值范围[1,5],通过设置此参数,获取在发音相似时的句子多侯选结果。设置多候选会影响性能,响应时间延迟200ms左右。 |
| wbest | 多候选-词级 | 取值范围[1,5],通过设置此参数,获取在发音相似时的词语多侯选结果。设置多候选会影响性能,响应时间延迟200ms左右。 |
| rlang | 繁体文字 | (仅中文支持)字体 zh-cn :简体中文(默认值) zh-hk :繁体香港 |
| domain | 垂直引擎 | 应用领域 iat:日常用语 medical:医疗 注:医疗领域若未授权无法使用,可到控制台-语音听写(流式版)-高级功能处添加试用或购买;若未授权无法使用会报错11200。 |
| pd | 领域个性化 | 仅中文支持)领域个性化参数 game:游戏 health:健康 shopping:购物 trip:旅行 |
注: 多候选效果是由引擎决定的,并非绝对的。即使设置了多候选,如果引擎并没有识别出候选的词或句,返回结果也还是单个。
# 2.3.4 识别结果
| JSON字段 | 英文全称 | 类型 | 说明 |
|---|---|---|---|
| sn | sentence | number | 第几句 |
| ls | last sentence | boolean | 是否最后一句 |
| bg | begin | number | 保留字段,无需关注 |
| ed | end | number | 保留字段,无需关注 |
| ws | words | array | 词 |
| cw | chinese word | array | 中文分词 |
| w | word | string | 单字 |
| sc | score | number | 分数 |
听写结果示例:
{
"sn": 1,
"ls": true,
"bg": 0,
"ed": 0,
"ws": [
{
"bg": 0,
"cw": [
{
"w": "今天",
"sc": 0
}
]
},
{
"bg": 0,
"cw": [
{
"w": "的",
"sc": 0
}
]
},
{
"bg": 0,
"cw": [
{
"w": "天气",
"sc": 0
}
]
},
{
"bg": 0,
"cw": [
{
"w": "怎么样",
"sc": 0
}
]
},
{
"bg": 0,
"cw": [
{
"w": "。",
"sc": 0
}
]
}
]
}
多候选结果示例:
{
"sn": 1,
"ls": false,
"bg": 0,
"ed": 0,
"ws": [
{
"bg": 0,
"cw": [
{
"w": "我想听",
"sc": 0
}
]
},
{
"bg": 0,
"cw": [
{
"w": "拉德斯基进行曲",
"sc": 0
},
{
"w": "拉得斯进行曲",
"sc": 0
}
]
}
]
}
# 3、常见问题
# 错误码及相应解决方案查询网址
# 获取到语音听写结果为空或错误内容或者内容不全的原因是什么?
答:原因可能是:
1、音频格式不正确,客户端支持的音频编解码算法只支持16位Intel PCM格式的音频,请使用Cool Edit Pro工具(网页搜索下载即可)查看音频格式,sdk目前支持的格式是 pcm 和 wav 格式、音频采样率要是 16k 或者 8k、采样精度16 位、单声道音频。请使用cool edit软件(网页搜索下载此软件即可)查看音频格式是否满足相应的识别引擎类型
2、QISRSessionBegin的参数设置不正确,如没有设置好正确的引擎类型等。
3、音频中间有静音或者杂音音频超过了后端点(默认为2000ms)的设置,此时请使用Cool Edit Pro工具查看音频内容,并且设置后端点(vad_eos)为最大值10000ms
包含超过后端点最大值的静音或者杂音音频识别不完整是正常的。
# 能获取到语音听写结果但是不全
答:此问题主要是在调用QISRAudioWrite时没有正确设置参数audioStatus所致,此参数在写入非最后一个音频数据块时需要设置为2,写入最后一个数据块时需要设置为4,以告诉MSC音频写入完毕。如果只有一个音频数据块,audioStatus也需要设置为4。
# 可以拿到识别/听写结果但是响应很慢
答:此问题可以尝试如下方法来解决: 调用QISRAudioWrite接口写音频数据时,尽量做到“匀速发送”——周期性的发送定长数据,做到边录边发,避免一次发送数据量过大的音频。 采用QISRAudioWrite接口和QISRGetResult接口混调的方式。在调用QISRAudioWrite接口时,可以检查out型参数recogStatus,如果其值为0,表明已经有(部分)识别结果缓存在MSC中了,此时可以调用QISRGetResult来获取结果。
# 如何设置语音云服务URL?
答:在MSPLogin接口中添加:server_url = http://YourDomainName/msp.do (YourDomainName是指语音云服务域名,请开发者自行替换) 例如:MSPLogin(NULL, NULL, "appid = 12345678, server_url = http://sdk.openspeech.cn/msp.do"); 注意:各参数间,以英文逗号分隔。 接口原型: int MSPLogin(const char* usr, const char* pwd, const char* params)
# SDK形式是否支持多路并发?
答:sdk:客户端解决方案,支持Android、ios、windows、linux等平台,不支持并发; webapi:服务端解决方案,不限制平台、不限制语言,支持并发。
# 如何设置识别业务所需的额外参数(其它业务类似)?
答:如要设置参数:vad_eos = 10000和vad_bos = 10000
const char* session_begin_params = "sub = iat, domain = iat, language = zh_cn, accent = mandarin, sample_rate = 16000, result_type = plain, result_encoding = utf8, vad_eos = 10000, vad_bos = 10000";
各类参数设置参考 MSC Linux API 文档 (opens new window)
# 语音听写支持识别多长时间的音频,支持的音频格式是什么?
答:语音听写的功能是可以识别60S以内的短音频,将音频转化成文本信息。
听写sdk目前支持的格式是 pcm 和 wav 格式、音频采样率要是 16k 或者 8k、采样精度16 位、单声道音频。请使用cool edit软件(网页搜索下载此软件即可)查看音频格式是否满足相应的识别引擎类型,否则识别为空或者识别为错误文本,格式必须正确,除上述格式均不识别,音频格式一定要满足要求。现语音听写WebAPI接口的中文普通话和英文支持mp3格式,如有需要,请参考语音听写(流式版)WebAPI (opens new window)
具体可以参考:http://bbs.xfyun.cn/forum.php?mod=viewthread&tid=7051
另外我们识别的音频长度最大为 60S,在使用音频是要注意你的本地音频的参数要和代码里的读取音频参数保持一致
# Linux听写sdk如何下载?
答:文档中心---快速指引 (opens new window)有介绍步骤---根据步骤下载Linux在线听写sdk
# SDK是否支持本地语音能力?
答:Linux平台SDK已经支持本地合成、本地命令词识别、本地语音唤醒功能了,创建应用后前往应用控制台下载各服务sdk即可。
# 如何不生成日志?
答:删除msc文件夹下的msc.cfg即可。

