# 语音听写 iOS SDK 文档
# 1、简介
语音听写,是基于自然语言处理,将自然语言音频转换为文本输出的技术。语音听写技术与语法识别技术的不同在于,语音听写不需要基于某个具体的语法文件,其识别范围是整个语种内的词条。在听写时,应用还可以上传个性化的词表,如联系人列表等,提高列表中词语的匹配率(见后面章节)。
自2019/8/16起,高阶功能-动态修正免费开放!可到这里 动态修正效果 (opens new window) 在线体验
使用方法详见 动态修正
语音听写详细的接口介绍及说明请参考: MSC iOS API 文档 (opens new window), 在集成过程中如有疑问,可登录讯飞开放平台论坛 (opens new window),查找答案或与其他开发者交流。
听写支持在线和离线两种工作方式,默认使用在线方式。如果使用离线服务,有2种方式,一种是使用语记SDK(原语音+ SDK)提供的免费服务,一种是付费购买后在应用内部集成。相关细节请关注讯飞开放平台( http://www.xfyun.cn/ )
MSC SDK的主要功能接口如下图所示):
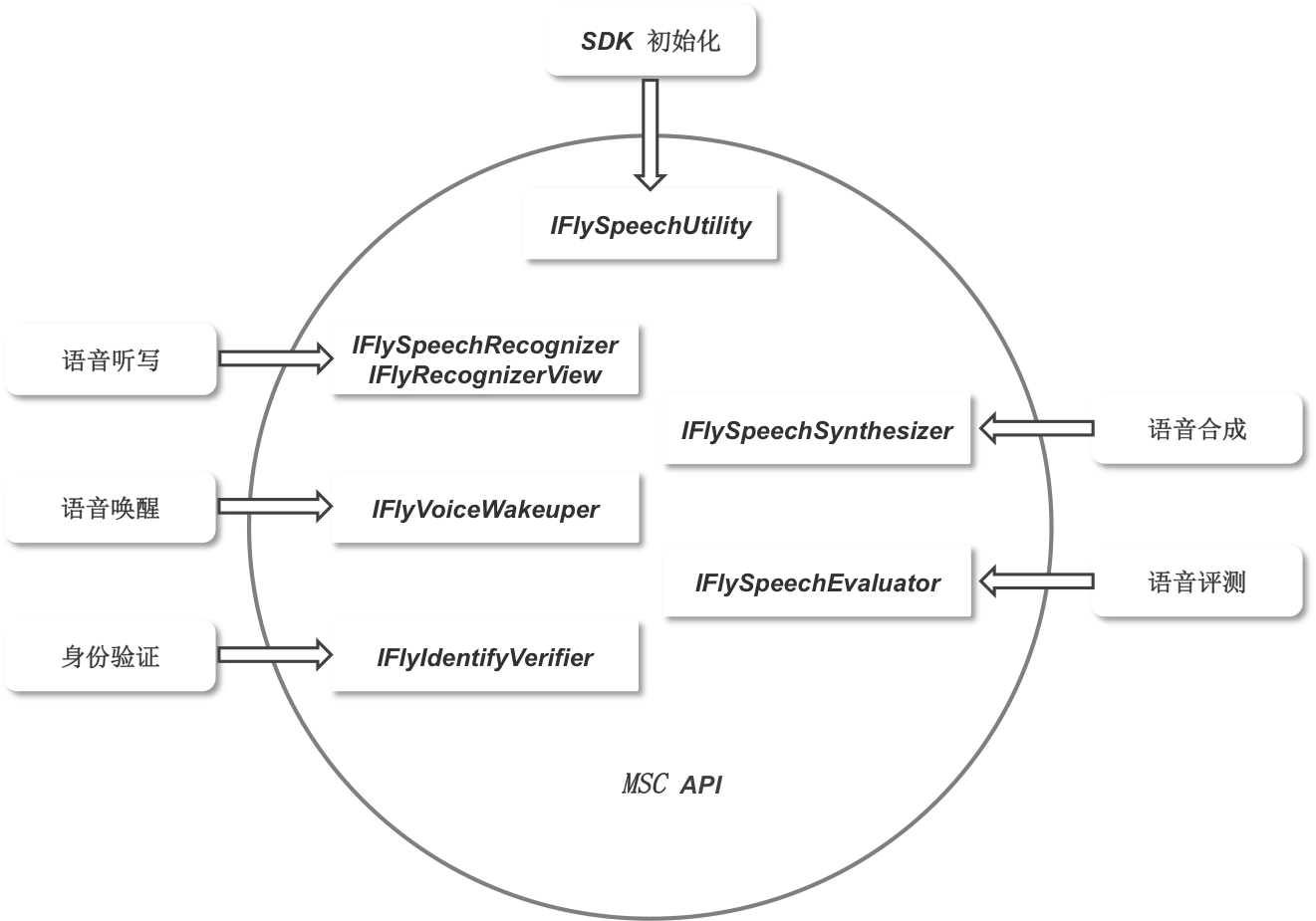
小语种:
- 目前小语种已经适配日语、俄语、西班牙语、法语、韩语,其他小语种敬请期待!
# 2、SDK集成指南
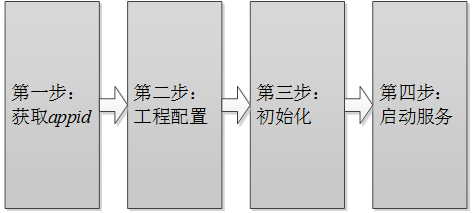
# 第一步:获取appid
appid是第三方应用集成讯飞开放平台SDK的身份标识,SDK静态库和appid是绑定的,每款应用必须保持唯一,否则会出现10407错误码。appid在开放平台申请应用时可以获得,下载SDK后可从SDK中sample文件夹的Demo工程里找到(例如: /sample/MSCDemo/MSCDemo/Definition.h 的APPID_VALUE)。
# 第二步:工程配置
# 添加库
将开发工具包中lib目录下的iflyMSC.framework添加到工程中。同时请将Demo中依赖的其他库也添加到工程中。 按下图示例添加 SDK 所需要的 iOS系统库:
| 库名称 | 添加范围 | 功能 |
|---|---|---|
| iflyMSC.framework | 必要 | 讯飞开放平台静态库。 |
| libz.tbd | 必要 | 用于压缩、加密算法。 |
| AVFoundation.framework | 必要 | 用于系统录音和播放 。 |
| SystemConfiguration.framework | 系统库 | 用于系统设置。 |
| Foundation.framework | 必要 | 基本库。 |
| CoreTelephony.framework | 必要 | 用于电话相关操作。 |
| AudioToolbox.framework | 必要 | 用于系统录音和播放。 |
| UIKit.framework | 必要 | 用于界面显示。 |
| CoreLocation.framework | 必要 | 用于定位。 |
| Contacts.framework | 必要 | 用于联系人。 |
| AddressBook.framework | 必要 | 用于联系人。 |
| QuartzCore.framework | 必要 | 用于界面显示。 |
| CoreGraphics.framework | 必要 | 用于界面显示。 |
| libc++.tbd | 必要 | 用于支持C++。 |
注意:
- 添加iflyMSC.framework时,请检查工程BuildSetting中的framwork path的设置,如果出现找不到framework的情况,可以将path清空,在Xcode中删除framework,然后重新添加。
- iflyMSC.framework最低支持iOS 8.0。
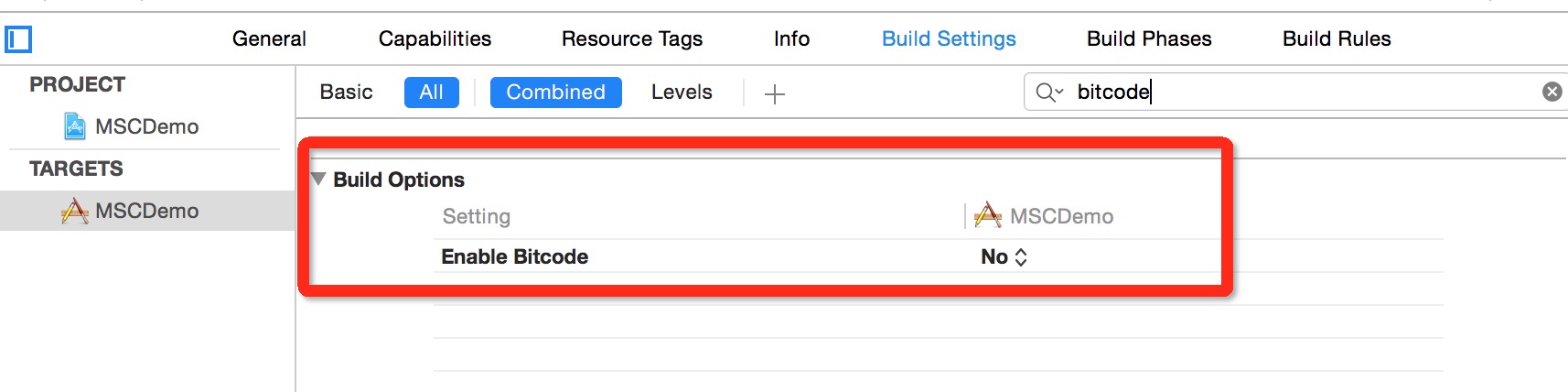
# 设置Bitcode
在Xcode 7,8默认开启了Bitcode,而Bitcode 需要工程依赖的所有类库同时支持。MSC SDK暂时还不支持Bitcode,可以先临时关闭。后续MSC SDK支持Bitcode 时,会在讯飞开放平台上进行SDK版本更新,请关注。关闭此设置,只需在Targets - Build Settings 中搜索Bitcode 即可,找到相应选项,设置为NO。
# 用户隐私权限配置
iOS 10发布以来,苹果为了用户信息安全,加入隐私权限设置机制,让用户来选择是否允许。 隐私权限配置可在info.plist 新增相关privacy字段,MSC SDK中需要用到的权限主要包括麦克风权限、联系人权限和地理位置权限:
<key>NSMicrophoneUsageDescription</key>
<string></string>
<key>NSLocationUsageDescription</key>
<string></string>
<key>NSLocationAlwaysUsageDescription</key>
<string></string>
<key>NSContactsUsageDescription</key>
<string></string>
即在Info.plist 中增加下图设置:

# 第三步:初始化
初始化示例:
//Appid是应用的身份信息,具有唯一性,初始化时必须要传入Appid。
NSString *initString = [[NSString alloc] initWithFormat:@"appid=%@", @"YourAppid"];
[IFlySpeechUtility createUtility:initString];
| 参数 | 说明 | 必填 |
|---|---|---|
| appid | 8位16进制数字字符串,应用的唯一标识,与下载的SDK一一对应。 | 是 |
| usr | 保留字段,无需关注。 | 否 |
| pwd | 保留字段,无需关注。 | 否 |
注意: 初始化是一个异步过程,可放在App启动时执行初始化,具体代码可以参照Demo的MSCAppDelegate.m。
# 第四步:启动服务
所有的服务皆遵循如下的流程,如下图:
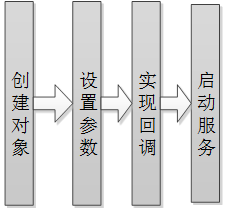
所有服务的API详细说明可参见:http://mscdoc.xfyun.cn/ios/api/
# 第五步:语音听写
IFlySpeechRecognizer是不带界面的语音听写控件,IFlyRecognizerView是带界面的控件,此处仅介绍不带界面的语音听写控件。使用示例如下所示:
//需要实现IFlyRecognizerViewDelegate识别协议
@interface IATViewController : UIViewController<IFlySpeechRecognizerDelegate>
//不带界面的识别对象
@property (nonatomic, strong) IFlySpeechRecognizer *iFlySpeechRecognizer;
@end
//创建语音识别对象
_iFlySpeechRecognizer = [IFlySpeechRecognizer sharedInstance];
//设置识别参数
//设置为听写模式
[_iFlySpeechRecognizer setParameter: @"iat" forKey: [IFlySpeechConstant IFLY_DOMAIN]];
//asr_audio_path 是录音文件名,设置value为nil或者为空取消保存,默认保存目录在Library/cache下。
[_iFlySpeechRecognizer setParameter:@"iat.pcm" forKey:[IFlySpeechConstant ASR_AUDIO_PATH]];
//启动识别服务
[_iFlySpeechRecognizer start];
//IFlySpeechRecognizerDelegate协议实现
//识别结果返回代理
- (void) onResults:(NSArray *) results isLast:(BOOL)isLast{}
//识别会话结束返回代理
- (void)onCompleted: (IFlySpeechError *) error{}
//停止录音回调
- (void) onEndOfSpeech{}
//开始录音回调
- (void) onBeginOfSpeech{}
//音量回调函数
- (void) onVolumeChanged: (int)volume{}
//会话取消回调
- (void) onCancel{}
# 第六步:音频流识别
音频流识别功能可以让开发者将已录制好的音频数据写入听写控件,最后得到识别结果。
//设置音频源为音频流(-1)
[self.iFlySpeechRecognizer setParameter:@"-1" forKey:@"audio_source"];
//启动识别服务
[self.iFlySpeechRecognizer startListening];
//写入音频数据
NSData *data = [NSData dataWithContentsOfFile:_pcmFilePath]; //从文件中读取音频
[self.iFlySpeechRecognizer writeAudio:data];//写入音频,让SDK识别。建议将音频数据分段写入。
//音频写入结束或出错时,必须调用结束识别接口
[self.iFlySpeechRecognizer stopListening];//音频数据写入完成,进入等待状态
# 3、常用参数说明
| 参数名称 | 名称 | 说明 |
|---|---|---|
| domain | 应用领域 | 应用领域 iat:日常用语 medical:医疗 注:医疗领域若未授权无法使用,可到控制台-语音听写(流式版)-高级功能处添加试用或购买;若未授权无法使用会报错11200。 |
| language | 语言区域 | 选择要使用的语言区域,,目前iOS SDK支持 zh_cn:中文 en_us:英文 ja_jp:日语 ko_kr:韩语 ru-ru:俄语 fr_fr:法语 es_es:西班牙语 注:小语种若未授权无法使用会报错11200,可到控制台-语音听写(流式版)-方言/语种处添加试用或购买。 |
| accent | 方言 | 当前仅在LANGUAGE为简体中文时,支持方言选择,其他语言区域时,可把此参数值设为mandarin。默认值:mandarin,其他方言参数可在控制台方言一栏查看。 |
| vad_bos | 前端点检测 | 开始录入音频后,音频前面部分最长静音时长,取值范围[0,10000ms],默认值5000ms |
| vad_eos | 后端点检测 | 开始录入音频后,音频后面部分最长静音时长,取值范围[0,10000ms],默认值1800ms。 |
| sample_rate | 采样率 | 支持:8KHZ,16KHZ |
| nbest | 句子多侯选 | 通过设置此参数,获取在发音相似时的句子多侯选结果。设置多候选会影响性能,响应时间延迟200ms左右。取值范围:听写[1,5]。 |
| wbest | 词语多侯选 | 通过设置此参数,获取在发音相似时的词语多侯选结 果。设置多候选会影响性能,响应时间延迟200ms左右。取值范围:听写[1,5]。 如: [_iflyRecognizerView setParameter:@"2" forKey:@"wbest"]; |
| result_type | 结果类型 | 结果类型包括:xml, json, plain。xml和json即对应的结构化文本结构,plain即自然语言的文本。 |
| nunum | 数字结果 | 通过设置此参数可偏向输出数字结果格式 0:倾向于汉字, 1:倾向于数字, |
| ptt | 标点符号 | (仅中文支持)标点符号添加 1:开启(默认值) 0:关闭 |
注: 多候选效果是由引擎决定的,并非绝对的。即使设置了多候选,如果引擎并没有识别出候选的词或句,返回结果也还是单个。
# 4、语音听写结果说明
| JSON字段 | 英文全称 | 类型 | 说明 |
|---|---|---|---|
| sn | sentence | int | 第几句 |
| ls | last sentence | boolean | 是否最后一句 |
| bg | begin | int | 保留字段,无需关注 |
| ed | end | int | 保留字段,无需关注 |
| ws | words | array | 词 |
| cw | chinese word | array | 中文分词 |
| w | word | string | 单字 |
| sc | score | int | 分数 |
语音听写结果示例:
{
"sn": 1,
"ls": true,
"bg": 0,
"ed": 0,
"ws": [
{
"bg": 0,
"cw": [
{
"w": " 今天 ",
"sc": 0
}
]
},
{
"bg": 0,
"cw": [
{
"w": " 的",
"sc": 0
}
]
},
{
"bg": 0,
"cw": [
{
"w": " 天气 ",
"sc": 0
}
]
},
{
"bg": 0,
"cw": [
{
"w": " 怎么样 ",
"sc": 0
}
]
},
{
"bg": 0,
"cw": [
{
"w": " 。",
"sc": 0
}
]
}
]
}
多候选结果示例:
{
"sn": 1,
"ls": false,
"bg": 0,
"ed": 0,
"ws": [
{
"bg": 0,
"cw": [
{
"w": "我想听",
"sc": 0
}
]
},
{
"bg": 0,
"cw": [
{
"w": "拉德斯基进行曲",
"sc": 0
},
{
"w": "拉得斯进行曲",
"sc": 0
}
]
}
]
}
# 动态修正
- 未开启动态修正:实时返回识别结果,每次返回的结果都是对之前结果的追加;
- 开启动态修正:实时返回识别结果,每次返回的结果有可能是对之前结果的的追加,也有可能是要替换之前某次返回的结果(即修正);
- 开启动态修正,相较于未开启,返回结果的颗粒度更小,视觉冲击效果更佳;
- 使用动态修正功能直接设置相应参数即可使用,参数设置方法:dwa=wpgs ;
- 动态修正功能仅 中文 支持;
未开启与开启返回的结果格式不同,若设置了动态修正参数:dwa=wpgs(仅中文支持),会有如下字段返回:
| 参数 | 类型 | 描述 |
|---|---|---|
| pgs | string | 开启wpgs会有此字段 取值为 "apd"时表示该片结果是追加到前面的最终结果;取值为"rpl" 时表示替换前面的部分结果,替换范围为rg字段 |
| rg | array | 替换范围,开启wpgs会有此字段 假设值为[2,5],则代表要替换的是第2次到第5次返回的结果 |
# 5、视频教程
# 6、代理服务器设置方法
在createUtility接口的params参数中添加:
net_type=custom, proxy_ip=<host>, proxy_port=<port>
其中,<host>,<port>替换为实际的代理服务器地址和端口。
例如:
NSString *initString = [[NSString alloc] initWithFormat:@"appid=%@, net_type=custom, proxy_ip=192.168.1.2, proxy_port=8080", @"12345678"]; //注意:各参数间,以英文逗号分隔。
[IFlySpeechUtility createUtility:initString];
接口原型: (IFlySpeechUtility *)createUtility:(NSString *)params
注意: 若在设置代理参数后,使用语音服务过程中,报错10204/10205/10212等网络异常错误时,请查阅以下内容,做出相关操作:
讯飞语音SDK的通信协议使用的是标准HTTP1.1协议,其代理协议使用的是标准HTTP代理协议。
代理服务器需要支持全双工多问多答方式,即 pipeline 模式。
代理服务器不能对80端口做限制,不能对如下域名做拦截: hdns.openspeech.cn scs.openspeech.cn open.xf-yun.com dev.voicecloud.cn
需要确保代理服务器只负责转发数据包,不能改变数据包的完整性和时序性。
代理服务器在转发数据包时,不能在HTTP协议头部添加 IE6 标识头。
# 7、常见问题
# iOS常见问题资料
答:请参见论坛帖子:iOS MSC SDK常见问题总结 (opens new window)
# iOS听写sdk如何下载?
答:文档中心---快速指引 (opens new window)有介绍步骤---根据步骤下载iOS在线听写sdk
# SDK形式是否支持多路并发?
答:sdk:客户端解决方案,支持Android、ios、windows、linux等平台,不支持并发; webapi:服务端解决方案,不限制平台、不限制语言,支持并发。
# SDK是否支持本地语音能力?
答:iOS平台SDK已经支持本地合成、本地命令词识别、本地语音唤醒功能了,创建应用后前往应用控制台下载各服务sdk即可。
# 如何设置语音云服务URL
答:对于一些特殊服务,需要在createUtility接口中添加:server_url = http://YourDomainName/msp.do (YourDomainName是指语音云服务域名,请开发者自行替换) 例如:
NSString *initString = [[NSString alloc] initWithFormat:@"appid=%@,server_url=%@", @"12345678",@"http://sdk.openspeech.cn/msp.do"]; //注意:各参数间,以英文逗号分隔。
[IFlySpeechUtility createUtility:initString];
接口原型: (IFlySpeechUtility *)createUtility:(NSString *)params
# 如何处理iOS SDK音频服务
答:请参见论坛帖子:讯飞语音iOS SDK音频问题详解 (opens new window)
# 集成自己项目后报错10407。
答:一般是在自己的项目集成时,appid和库文件不匹配导致的。
# 是否支持x86架构?
答:目前不支持x86架构。
# 在听写过程中如果10秒未说话录制会自动停止。
答:听写vad_eos为支持的最长静音时间,超过这个时间会认为音频结束自动断开。
# 是否支持小语种?
答:目前小语种已经适配日语、俄语、西班牙语、法语、韩语,其他小语种敬请期待!
# 为什么超过一分钟的音频文件,一分钟后的部分无法识别?
答:听写支持识别60s之内的音频,超过一分钟是无法识别的。

